함수형 API는 다중 입력 모델을 만드는 데 사용할 수 있습니다. 일반적으로 이런 모델은 서로 다른 입력 가지를 합치기 위해 여러 텐서를 연결할 수 있는 층을 사용합니다. 텐서를 더하거나 이어 붙이는 식입니다. 관련한 keras함수는 keras.layers.add, keras.layers.concatenate 등입니다.
전형적인 질문-응답 모델은 2개의 입력을 가집니다. 하나는 자연어 질문이고, 또 하나는 답변에 필요한 정보가 담겨 있는 텍스트입니다. 그러면 모델은 답을 출력해야 합니다. 가장 간단한 구조는 미리 정의한 어휘 사전에서 소프트맥스 함수를 통해 한 단어로 된 답을 출력하는 것입니다.
1. 다중 입력 모델

1. 2개의 입력을 가진 질문-응답 모델의 함수형 API구현하기
from keras.models import Model
from keras import layers
from keras import Input
text_vocabulary_size = 10000
question_vocabulary_size = 10000
answer_vocabulary_size = 500
#텍스트 입력은 길이가 정해지지 않은 정수 시퀀스입니다. 입력 이름을 지정하 수 있습니다.
text_input = Input(shape=(None,), dtype='int32', name='text')
#입력을 크기가 64인 벡터의 시퀀스로 임베딩합니다.
embdded_text = layers.Embedding(text_vocabulary_size, 64)(text_input)
#LSTM으 사용하여 이 벡터들을 하나의 벡터로 인툉합니다.
encoded_text = layers.LSTM(32)(embdded_text)
#질문도 동일한 과정을 거칩니다.
question_input = Input(shape=(None,), dtype='int32', name = 'question')
#입력을 크기가 32인 벡터의 시퀀스로 임베딩합니다.
embdded_question = layers.Embedding(text_vocabulary_size, 32)(question_input)
#LSTM으 사용하여 이 벡터들을 하나의 벡터로 인툉합니다.
encoded_question = layers.LSTM(16)(embdded_question)
#인코딩된 질문과 테그트를 연결합니다.
concatenated = layers.concatenate([encoded_text, encoded_question])
#소프트맥스 분류기를 추가합니다.
answer = layers.Dense(answer_vocabulary_size, activation='softmax')(concatenated)
model = Model([text_input, question_input], answer)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc'])
2. 다중 입력 모델에 데이터 주입하기
num_samples = 1000
max_length = 100
# 입력으로 사용할 Data를 Random하게 Shpae를 맞춰서 선언한다.
text = np.random.randint(1, text_vocabulary_size, size=(num_samples, max_length))
question = np.random.randint(1, question_vocabulary_size, size=(num_samples, max_length))
# Target Data를 원핫 인코딩을 통하여 구성한다.
answers = np.random.randint(0, answer_vocabulary_size, size=num_samples)
answers = to_categorical(answers)
# 1.리스트 입력 사용
#model.fit([text, question], answers, epochs=10, batch_size=128)
# 2. 딕셔너리 입력을 사용하여 학습
model.fit({'text':text, 'question':question}, answers, epochs=10, batch_size=128)
2. 다중 출력 모델
같은 식으로 함수형 API를 사용하여 다중 출력모델을 만들 수 있습니다. 간단한 예는 데이터에 있는 여러 속성을 동시에 예측하는 네트워크입니다. 예를 들어 소셜 미디어에서 익명 사용자의 포스터를 입력으로 받아 그 사람의 나이, 성별, 소득 수준 등을 예측합니다.
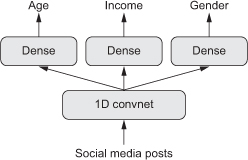
3. 3개의 출력을 가진 함수형 API구현하기
from keras import layers
from keras import Input
from keras.models import Model
vocabulary_size = 50000
num_income_groups = 10
posts_input = Input(shape=(None,), dtype='int32', name='posts')
embedded_posts = layers.Embedding(vocabulary_size, 256)(posts_input)
x = layers.Conv1D(128, 5, activation='relu')(embedded_posts)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.MaxPooling1D(5)(x)
x = layers.Dense(128, activation='relu')(x)
#출력 층에 이름을 지정합니다.
age_prediction = layers.Dense(1, name='age')(x)
income_prediction = layers.Dense(num_income_groups, activation='softmax', name='income')(x)
gender_prediction = layers.Dense(1, activation='sigmoid', name='gender')(x)
model = Model(posts_input, [age_prediction, income_prediction, gender_prediction])
이런 모델을 훈련시키려면 네트워크 출력마다 다른 손실 함수를 지정해야 합니다. 예를 들어 나이 예측은 스칼라 회귀 문제이지만 성멸 예측은 이진 클래스 문제라 훈련 방식이 다릅니다. 경사 하강법은 하나의 스칼라 값을 최소화하기 때문에 모델을 훈련하려면 이 손실들을 하나의 값으로 합쳐야 합니다.
손실 값을 합치는 가장 간단한 방법은 모두 더하는 것입니다. keras에서는 compile메서드에 리스트나 딕셔너리를 사용하여 출력마다 다른 손실을 지정할 수 있습니다. 계산된 손실값은 전체 손실 하나로 더해지고 훈련 과정을 통해 최소화됩니다.
model.compile(optimizer='rmsprop', loss=['mse','categorical_crossentropy', 'binary_crossentropy'])
손실 값이 많이 불균형하면 모델이 개별 손실이 가장 큰 작업에 치우쳐 표현을 최적화할 것입니다. 그 결과 다른 작업들은 손해를 입습니다. 이를 해결하기 위해 손실 값이 최종 손실에 기여하는 수준을 지정할 수 있습니다. 특히 손실 값의 스케일이 다를 때 유용합니다.
예를 들어 나이 회귀 작업에 사용되는 평균 제곱 오차(MSE)손실은 일반적으로 3~5사이의 값을 가집니다. 반면에 성별 분류 작업에 사용되는 크로스엔트로피 손실은 0.1정도로 낮습니다. 이런 환경에서 손실에 균형을 맞추려면 크로스엔트로피 손실에 가중치 10을 주고 MSE손실에 가중치 0.25를 줄 수 있습니다.
model.compile(optimizer='rmsprop', loss={'age':'mse','income':'categorical_crossentropy', 'gender':'binary_crossentropy'}, loss_weights={'age':0.25, 'income':1., 'gender':10.})
다중 입력 모델과 마찬가지로 넘파이 배열의 리스트나 딕셔너리를 모델에 전달하여 훈련합니다.
import numpy as np
from tensorflow.keras.utils import to_categorical
num_samples = 1000
max_length = 100
posts = np.random.randint(0, vocabulary_size, size=num_samples)
age_targets = np.random.randint(0, vocabulary_size, size=num_samples)
age_targets = to_categorical(age_targets)
income_targets = np.random.randint(0, vocabulary_size, size=num_samples)
income_targets = to_categorical(income_targets)
gender_targets = np.random.randint(0, vocabulary_size, size=num_samples)
gender_targets = to_categorical(gender_targets)
에러 발생, --will be updated
model.fit(posts, [age_targets, income_targets, gender_targets], epochs=10, batch_size=64)
# model.fit(posts, {'age': age_targets, 'income': income_targets,'gender': gender_targets}, epochs=10, batch_size=64)'Lecture AI > 7장.Sequential 모델을 넘어서: 케라스의 함수형 API' 카테고리의 다른 글
| 2. 함수형 API 소개 (0) | 2021.07.14 |
|---|---|
| 1. Sequential 모델을 넘어서는 케라스의 함수형 API (0) | 2021.07.14 |

