본 장에서는 연속적인 값을 예측하는 회귀에 대해 알아보겠습니다.
데이터 준비
상이한 스케일을 가진 값을 신경망에 주입하면 문제가 됩니다. 네트워크가 이런 다양한 데이터에 자동으로 맞추려고 할 수 있지만 이는 확실히 학습을더 어렵게 만듭니다. 이런 데이터를 다룰때 대표적인 방법은 특성별로 정규화를 하는 것입니다. 입력 데이터에 있는 각 특성에 대해서 특성의 평균을 빼고 표준 편차로 나눕니다. 특성의 중앙이 0근처에 맞추어지고 표준 편차가 1이 됩니다.
from keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std테스트 데이터를 정규화할 때 사용한 값이 훈련 데이터에서 계산한 값임을 주목하세요. 머신 러닝 작업 과정에서 절대로 테스트 데이터에서 계산한 어떤 값도 사용해서는 안 됩니다. 데이터 정규화처럼 간단한 작업조차도 그렇습니다.
모델 구성
샘플 개수가 적기 때문에 64개의 유닛을 가진 2개의 은닉 층으로 작은 네트워크를 구성하여 사용하겠습니다. 일반적으로 훈련 데이터의 개수가 적을수록 과대적합이 더 쉽게 일어나므로 작은 모델을 사용하는 것이 과대적합을 피하는 한 방법입니다.
from keras import models
from keras import layers
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mse'])
return model
이 네트워크의 마지막 층은 하나의 유닛을 가지고 있고 활성화 함수가 없습니다.(선형층이라고 부릅니다). 이것이 전형적인 스칼라 회귀(하나의 연속적인 값을 예측하는 회귀)를 위한 구성입니다. 활성화 함수를 적용하면 출력 값의 범위를 제한하게 됩니다. 예를 들어 마지막 층에 sigmoid활성화 함수를 적용하면 네트워크가 0과 1사이의 값을 예측하도록 학습될 것입니다. 여기서는 마지막 층이 순수한 선형이므로 네트워크가 어떤 범위의 값이라도 예측하도록 자유롭게 학습됩니다.
이 모델은 mse손실 함수를 사용하여 컴파일합니다. 이 함수는 평균 제곱 오차(mean squared error, MSE)의 약어로 예측과 타깃 사이 거리의 제곱입니다. 회귀 문제에서 널리 사용되는 손실 함수입니다. 훈련하는 동안 모니텅을 위해 새로운 지표인 평균 절대 오차(mean absolute error, MAE) 이는 예측과 타깃 사이 거리의 절댓값입니다.
K-fold 검증
#kfold
import numpy as np
k=2
num_val_samples = len(train_data)//k
num_epochs = 500
all_scores = []
all_mae_histories = []
for i in range(k):
print('처리중인 폴드 #', i)
#검증 데이터 준비: k번째 분할
val_data = train_data[i*num_val_samples:(i+1)*num_val_samples]
val_targets = train_targets[i*num_val_samples: (i+1)*num_val_samples]
#훈련 데이터 준비:다른 분할 전체
partial_train_data = np.concatenate([train_data[:i*num_val_samples], train_data[(i+1)*num_val_samples:]], axis=0)
partial_train_targets = np.concatenate([train_targets[:i*num_val_samples], train_targets[(i+1)*num_val_samples:]], axis=0)
#케라스 모델 구성(컴파일 포함)
model = build_model()
#모델 훈련(verbose=0이므로 훈련 관정이 출력되지 않습니다)
history = model.fit(partial_train_data, partial_train_targets, validation_data=(val_data, val_targets), epochs=num_epochs, batch_size=1, verbose=0)
# history_dict = history.history
# print(history_dict.keys())
# dict_keys(['loss', 'mse', 'val_loss', 'val_mse'])
#검증 세트로 모델 평가
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
mae_history = history.history['val_mse']
all_mae_histories.append(mae_history)
all_scores.append(val_mae)
모든 폴드에 대해 에포크의 MAE점수 평균을 계산합니다.
average_mae_history = [np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
# print(average_mae_history)
검증 점수에 대한 그래프를 그린다.
import matplotlib.pyplot as plt
plt.plot(range(1, len(average_mae_history)+1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
그래프를 확인하면 범위가 크고 변동이 심하기 때문에 보기가 좀 어렵습니다.
- 곡선의 다른 부분과 스케일이 많이 다른 첫 10개의 데이터 포인트를 제외시킵니다.
- 부드러운 곡선을 얻기 위해 각 포인트를 이전 포인트의 지수 이동 평균으로 대체합니다.
def smooth_curve(points, factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous*factor+point*(1-factor))
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1, len(smooth_mae_history)+1), smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()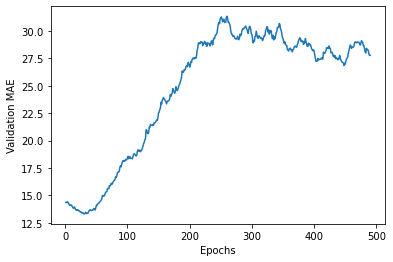
이 그래프를 보면 검증 MAE가 80번째 에포크 이후에 줄어드는 것이 멈추었ㅅㅂ니다. 이 지점 이후로는 과대적합이 시작됩니다.
모델의 여러 매개변수에 대한 튜닝이 끝나면(에포크 수뿐만 아니라 은닉층의 크기도 조절하 수 있습니다.) 모든 훈련 데이터를 사용하고 최상의 매개변수로 최종 실전에 투입될 모델을 훈련시킵니다.
model = build_model()
model.fit(train_data, train_targets, epochs=80, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
print(test_mse_score, test_mae_score)
정리
- 회귀는 분류에서 사용했던 것과는 다른 손실 함수를 사용합니다. 평균 제곱 오차(MSE)는 회귀에서 자주 사용되는 손실 함수입니다.
- 비슷하게 회귀에서 사용되는 평가 지표는 분류와 다릅니다. 당연히 정확도 개념은 회귀에 적용되지 않습니다. 일반적인 회귀 지표는 평균 절대 오차(MAE)입니다.
- 입력 데이터의 특성이 서로 다른 범위를 가지면 전처리 단계에서 각 특성을 개별적으로 스케일 조정해야 합니다.
- 가용한 데이터가 적다면 kfold 검증을 사용하는 것이 신뢰할 수 있는 모델 평가 방법입니다.
- 가용한 훈련 데이터가 적다면 과대적합을 피하기위해 은닉층의 수를 줄인 모델이 좋습니다. (1개 혹은 2개)
'Lecture AI > 3장.신경망 시작하기' 카테고리의 다른 글
| 3. 뉴스 기사 분류 : 다중 분류 문제 (0) | 2021.07.18 |
|---|---|
| 2. 신경망을 이용한 IMDB 영화 리뷰 분류: 이진 분류 예제 (0) | 2021.07.18 |
| 1. 신경망의 구조에 대한 이해 (0) | 2021.07.17 |


