딥러닝의 작동 원리
층에서 입력 데이터가 처리되는 상세 내용은 일련의 숫자로 이루어진 층의 가중치(weight)에 저장되어 있습니다. 기술적으로 말하면 어떤 층에서 일어나는 변환은 그 층의 가중치를 파라미터(parameter)로 가지는 함수로 표현됩니다.
이런 맥락으로 보면 학습은 주어진 입력을 정확한 타깃에 매핑하기 위해 신경망의 모든 층에 있는 가중치 값을 찾는 것을 의미합니다. 하지만 어떤 심층 신경망은 수천만 개의 파라미터를 가지기도 합니다. 이런 경우에 모든 파라미터의 정확한 값을 찾는 것은 어려운 일로 보입니다. 파라미터 하나의 값을 바꾸면 다른 모든 파라미터에 영향을 끼치기 때문입니다.

신경망의 출력을 제어하려면 출력이 기대하는 것보다 얼마나 벗어났는지를 측정해야 합니다. 이는 신경망의 손실 함수(loss function)또는 목적 함수(objective funciton)가 담당하는 일입니다. 신경망이 한 샘플에 대해 얼마나 잘 예측했는지 측정하기 위해 손실 함수가 신경망의 예측과 진짜 타깃의 차이를 점수로 계산합니다.
기본적인 딥러닝 방식은 이 점수를 피드백 신호로 사용하여 현재 샘플의 손실 점수가 감소되는 방향으로 가중치 값을 조금씩 수정하는 것입니다. 이런 수정 과정은 딥러닝의 핵심 알고리즘인 역전파(BackPropaation) 알고리즘을 구현한 옵티마이저(Optimizer)가 담당합니다.
초기에는 네트워크의 가중치가 랜덤 한 값으로 할당되므로 랜덤 한 변환을 연속적으로 수행합니다. 자연스럽게 출력은 기대한 것과 멀어지고 손실 점수가 매우 높을 것입니다. 하지만 네트워크가 모든 샘플을 처리하면서 가중치가 조금씩 올바른 방향으로 조정되고 손실 점수가 감소합니다. 이를 훈련 반복(training loop)라고 합니다. 충분한 횟수만큼 반복하면(일반적으로 수천 개의 샘플에서 수십 번 반복하면) 손실 함수를 최소화하는 가중치 값을 산출합니다. 최소한의 손실을 내는 네트워크가 타깃에 가능한 가장 가까운 출력을 만드는 모델이 됩니다.
머신러닝에서는 정답이 있는 데이터셋을 사용할 때 지도 학습(supervised learning)이라고 말합니다. 이 경우 신경망을 개선하고자 훈련 예시를 사용한다. 테스트 데이터도 각 숫자와 관련된 정답을 갖고 있습니다. 하지만 레이블이 없다고 생각하고 신경망이 예측을 수행하면 나중에 레이블을 확인해 신경망이 얼마나 숫자를 잘 인식하는지 평가할 수 있습니다.
원핫 인코딩(OHE)
신경망 내부에 사용될 정보를 인코딩하는 간단한 도구로서 원핫 인코딩을 사용할 수 있습니다. 많은 범주형 특징을 숫자형 변수로 변환하면 좋을 때가 있다.
머신러닝 강좌 #4] 데이터 전처리 - 레이블 인코딩, 원-핫 인코딩
데이터 전처리(Data Preprocessing)은 머신러닝을 하는 데 있어 매우 중요합니다. 머신러닝에서는 결손값, 즉 NaN, Null값은 허용되지 않습니다. 따라서 이러한 Null값은 고정된 다른 값으로 변환해야 합
nicola-ml.tistory.com
텐서플로 2.0으로 단순 신경망 정의
단순한 신경망 프로그램을 만들어보겠습니다.
- EPOCH는 훈련을 얼마나 지속할 것인지
- BATCH_SIZE는 한 번에 신경망에 입력하는 표본의 수
- VALIDATION은 훈련 프로세스의 유효성을 확인하거나 증명하려고 남겨둔 데이터의 양
import tensorflow as tf
import numpy as np
from tensorflow import keras
# for reproducibility
np.random.seed(1671)
# network and training
EPOCHS = 200
BATCH_SIZE = 128
VERBOSE = 1
NB_CLASSES = 10 # number of outputs = number of digits
N_HIDDEN = 128
VALIDATION_SPLIT=0.2 # how much TRAIN is reserved for VALIDATION
# loading MNIST dataset
# verify
# the split between train and test is 60,000, and 10,000 respectly
# one-hot is automatically applied
mnist = keras.datasets.mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
#normalize in [0,1]
X_train, X_test = X_train / 255.0, X_test / 255.0
#X_train is 60000 rows of 28x28 values --> reshaped in 60000 x 784
RESHAPED = 784
#
X_train = X_train.reshape(60000, RESHAPED)
X_test = X_test.reshape(10000, RESHAPED)
Y_train = Y_train.astype('float32')
Y_test = Y_test.astype('float32')
model = tf.keras.models.Sequential()
model.add(keras.layers.Dense(NB_CLASSES, input_shape=(RESHAPED,),
kernel_initializer='zeros',
name='dense_layer',
activation='softmax'))
# summary of the model
model.summary()
# compiling the model
model.compile(optimizer='SGD',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#training the moodel
model.fit(X_train, Y_train,batch_size=BATCH_SIZE, epochs=EPOCHS,verbose=VERBOSE, validation_split=VALIDATION_SPLIT)
#evalute the model
test_loss, test_acc = model.evaluate(X_test, Y_test)
print('Test accuracy:', test_acc)
# making prediction
predictions = model.predict(X_test): SH (2021-10-24)
Step2. 모델 정의: 활성화 함수가 '소프트맥스(softmax)'인 단일 뉴런으로, 이는 시그모이드 함수를 일반화한 것이다. 앞서 설명한 대로 시그모이드 함수는 입력이 (-∞, ∞)에서 변화할 때, 출력은 (0, 1) 사이에 있다. 유사하게 소프트맥스는 임의의 실수 값의 K차원 벡터를 (0, 1) 범위의 실수 값을 가진 K차원 벡터로 '밀어 넣어' 총합이 1이 되게 한다.
model = tf.keras.models.Sequential()
model.add(keras.layers.Dense(NB_CLASSES,
input_shape=(RESHAPED,),
kernel_initializer='zeros',
name='dense_layer',
activation='softmax'))
Step 3. 컴파일 단계: 컴파일 단계는 몇 가지 설정 사항이 있다.
첫째, 모델을 훈련시키는 동안 가중치를 업데이트하는 데 사용되는 특정 알고리즘인 최적화기(Optimizer)를 선택해야 한다.
둘째, Optimizer가 가중치 공간을 탐색하는 데 사용 할 목적 함수(Objective function)를 선택해야 한다. (종종 목적 함수는 손실 함수(loss function)또는 비용 함수(cost functions)라고 하며, 최적화 프로세스는 손실 최소화 프로세스로 정의할 수 있다.)
셋째, 훈련된 모델을 평가해야 한다.
Opimizer에서 SGD는 최적화 알고리즘의 특별한 조율로서 각 훈련(epoch)마다 신경망의 오차를 줄이고자 사용된다.
자주 사용하는 목적함수
- MSE: 예측과 실제 값 사이의 평균 제곱 오차를 정의한다. 이 목적 함수는 각 예측에서 발생한 모든 오차의 평균이 된다는 점에 주목하자. 예측이 실제 값과 멀수록 이 거리는 제곱 연산에 의해 더욱 뚜렷해진다. 또한 제곱을 통해 오차가 양수이든 음수이든 누적 값을 증가시킨다.
- binary_crossentropy: 이진 로그 손실을 정의한다. 이진 로그 예측에 적절하다.
- categorical_crossentrop: 다분류 로그 손실을 정의한다. 범주형 교차 엔트로피는 예측 분포에 많이 사용을 하며 다분류 레이블 예측에 적합하다는 점에 주목하자. 또한 이 함수는 소프트맥스 활성화에 연계된 기본 선택 옵션이기도 하다.
일반적인 척도(metrics)에는 다음과 같은 것이 있다.
- 정확도(Accuracy): 타깃 대비 정확히 예측한 비율을 정의한다.
- 정밀도(Precision): 긍정으로 예측한 것 중 실제로 참인 것의 비율이다.
- 재현율(Recall) 올바로 예측한 것(참은 긍정, 거짓은 부정으로 예측) 중 긍정으로 예측한 것이 실제로 참인 비율을 의미한다.
머신러닝 강좌 #7] 머신러닝 모델 성능 평가 - 정확도 (Accuracy), Confusion Matrix
머신러닝 모델은 여러 가지 방법으로 예측 성능을 평가할 수 있습니다. 성능 평가 지표(Evaluation Metrics)는 일반적으로 모델이 분류냐 회귀냐에 따라 여러 종류로 나뉩니다. 회귀의 경우 대부분 실
nicola-ml.tistory.com
척도는 목적 함수와 유사하지만 모델 훈련에 사용되지 않고 모델 평가에만 사용된다는 점만 다르다. 그러나 척도와 목적 함수의 차이점을 이해하는 것이 중요하다. 앞서 설명한 것처럼 손실 함수는 신경망을 최적화하는 데 사용된다. 손실 함수는 선택한 최적화기에 의해 최소화되는 함수다. 반면 척도는 신경망의 성능을 판단하는 데 사용된다. 이는 평가를 위한 것이며 최적화 프로세스와 분리돼야 한다.
model.compile(optimizer='SGD',
loss='categorical_crossentropy',
metrics=['accuracy'])
SGD(확률적 그래디언트 하강)은 최적화 알고리즘의 특별한 종류로서 각 훈련 에폭(epoch)마다 신경망의 오차를 줄이고자 사용된다.
Step 4. 훈련 단계: 컴파일됐으면 fit() 메서드를 사용해서 훈련할 수 있고, 이때 몇 개의 매개변수를 명시할 수 있다.
- ephochs는 모델이 훈련 집합에 노출된 횟수다. 각 반복에서 optimizer는 목표 함수가 최소화되도록 가중치를 조정하려고 한다.
- batch_size는 Optimizer가 가중치 갱신을 수행하기 전에 관찰한 훈련 인스턴스의 수다. 일반적으로 한 에폭당 여러 배치가 있다.
model.fit(X_train, Y_train,
batch_size=BATCH_SIZE, epochs=EPOCHS,
verbose=VERBOSE, validation_split=VALIDATION_SPLIT)검증하고자 훈련 집합의 일부를 남겨둔 것에 주목하자. 핵심 아이디어는 훈련하는 동안 유효성 성능을 측정하고자 훈련 데이터의 일부를 남겨둔다는 것이다. 이는 머신러닝 과제에서 준수해야 할 좋은 관행이다.
Step5. 모델 평가 단계: evaluate(X_test, Y_test) 메서드를 사용해 test_loss와 test_acc를 계산할 수 있다.
test_loss, test_acc = model.evaluate(X_test, Y_test)
print('Test accuracy:', test_acc)
Step6. 결과: Train Accuracy: 92%, Validation Accuracy: 92%, Test Accurcy: 92%

텐서플로 2.0의 단순 신경망을 은닉층으로 개선
위의 정확성을 높이기 위해 신경망에 계층을 추가하는 것이다. 직관적으로 이러한 추가 뉴런은 훈련 데이터에서 좀 더 복잡한 패턴을 학습하는 데 도움이 될 수 있기 때문이다.
즉, 계층을 추가하면 매개변수가 추가돼 모델이 더 복잡한 패턴을 기억할 수 있게 된다. 이제 입력 계층 다음으로 N_HIDDEN뉴런과 활성화 함수 ReLU가 있는 첫 번째 밀집(dense) 계층을 갖도록 추가한다. 이 추가 계층은 입력 또는 출력과 직접 연결되지 않기 때문에 숨겨진(은닉) hidden 것으로 간주된다.
첫 번째 은닉층 뒤에 N_HIDDEN뉴런을 가진 두 번째 은닉층이 있고 그다음으로 10개의 뉴런을 가진 출력 계층이 있다. 각각의 뉴런은 연관된 숫자가 인식될 때 발화한다.
import tensorflow as tf
import numpy as np
from tensorflow import keras
# network and training
EPOCHS = 50
BATCH_SIZE = 128
VERBOSE = 1
NB_CLASSES = 10 # number of outputs = number of digits
N_HIDDEN = 128
VALIDATION_SPLIT=0.2 # how much TRAIN is reserved for VALIDATION
# loading MNIST dataset
# verify
# the split between train and test is 60,000, and 10,000 respectly
# one-hot is automatically applied
mnist = keras.datasets.mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
#X_train is 60000 rows of 28x28 values --> reshaped in 60000 x 784
RESHAPED = 784
#
X_train = X_train.reshape(60000, RESHAPED)
X_test = X_test.reshape(10000, RESHAPED)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
#normalize in [0,1]
X_train, X_test = X_train / 255.0, X_test / 255.0
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
#one-hot
Y_train = tf.keras.utils.to_categorical(Y_train, NB_CLASSES)
Y_test = tf.keras.utils.to_categorical(Y_test, NB_CLASSES)
#build the model
model = tf.keras.models.Sequential()
model.add(keras.layers.Dense(N_HIDDEN,
input_shape=(RESHAPED,),
name='dense_layer', activation='relu'))
model.add(keras.layers.Dense(N_HIDDEN,
name='dense_layer_2', activation='relu'))
model.add(keras.layers.Dense(NB_CLASSES,
name='dense_layer_3', activation='softmax'))
# summary of the model
model.summary()
# compiling the model
model.compile(optimizer='SGD',
loss='categorical_crossentropy',
metrics=['accuracy'])
#training the model
model.fit(X_train, Y_train,
batch_size=BATCH_SIZE, epochs=EPOCHS,
verbose=VERBOSE, validation_split=VALIDATION_SPLIT)
#evaluate the model
test_loss, test_acc = model.evaluate(X_test, Y_test)
print('Test accuracy:', test_acc)
# making prediction
predictions = model.predict(X_test)
Train Accuracy: 92%, Validation Accuracy: 92%, Test Accurcy: 92%

일정 에폭을 넘어서면 개선이 중지되거나 거의 감지할 수 없을 정도가 된다는 점에 주목하자. 머신러닝에서는 이러한 현상을 수렴(Convergence)이라고 한다.
텐서플로 2.0의 드롭아웃으로 단순망 개선
이제 Dropout확률로 훈련 중에 은닉층 내부 밀집 신경망에 전파된 값 중 일부를 무작위로 제거해보자. 머신러닝에서 이는 잘 알려진 정규화의 한 형태다. 놀랍게도, 몇 가지 값을 무작위로 삭제한다는 아이디어를 통해 성능을 향상할 수 있다. 이 개선의 기본 개념은 무작위 드롭아웃(random dropout)으로 신경망의 일반화를 향상시키는 데 도움이 되는 유용한 중복 패턴을 학습시킨다는 것이다.
import tensorflow as tf
import numpy as np
from tensorflow import keras
#for tensorboard
from tensorflow.keras.callbacks import TensorBoard
tensorboard_callback = TensorBoard('.logdir')
# network and training
EPOCHS = 50
BATCH_SIZE = 128
VERBOSE = 1
NB_CLASSES = 10 # number of outputs = number of digits
N_HIDDEN = 128
VALIDATION_SPLIT=0.2 # how much TRAIN is reserved for VALIDATION
DROPOUT = 0.3
# loading MNIST dataset
# verify
# the split between train and test is 60,000, and 10,000 respectly
# one-hot is automatically applied
mnist = keras.datasets.mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
#X_train is 60000 rows of 28x28 values --> reshaped in 60000 x 784
RESHAPED = 784
#
X_train = X_train.reshape(60000, RESHAPED)
X_test = X_test.reshape(10000, RESHAPED)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
#normalize in [0,1]
X_train, X_test = X_train / 255.0, X_test / 255.0
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
#one-hot
Y_train = tf.keras.utils.to_categorical(Y_train, NB_CLASSES)
Y_test = tf.keras.utils.to_categorical(Y_test, NB_CLASSES)
#build the model
model = tf.keras.models.Sequential()
model.add(keras.layers.Dense(N_HIDDEN,
input_shape=(RESHAPED,),
name='dense_layer', activation='relu'))
model.add(keras.layers.Dropout(DROPOUT))
model.add(keras.layers.Dense(N_HIDDEN,
name='dense_layer_2', activation='relu'))
model.add(keras.layers.Dropout(DROPOUT))
model.add(keras.layers.Dense(NB_CLASSES,
name='dense_layer_3', activation='softmax'))
# summary of the model
model.summary()
# compiling the model
model.compile(optimizer='RMSProp',
loss='categorical_crossentropy',
metrics=['accuracy'])
#training the moodel
model.fit(X_train, Y_train,
batch_size=BATCH_SIZE, epochs=EPOCHS,
verbose=VERBOSE, validation_split=VALIDATION_SPLIT,
callbacks=[tensorboard_callback])
#evalute the model
test_loss, test_acc = model.evaluate(X_test, Y_test)
print('Test accuracy:', test_acc)
# making prediction
predictions = model.predict(X_test)
Train Accuracy: 98%, Validation Accuracy: 97%, Test Accurcy: 97%
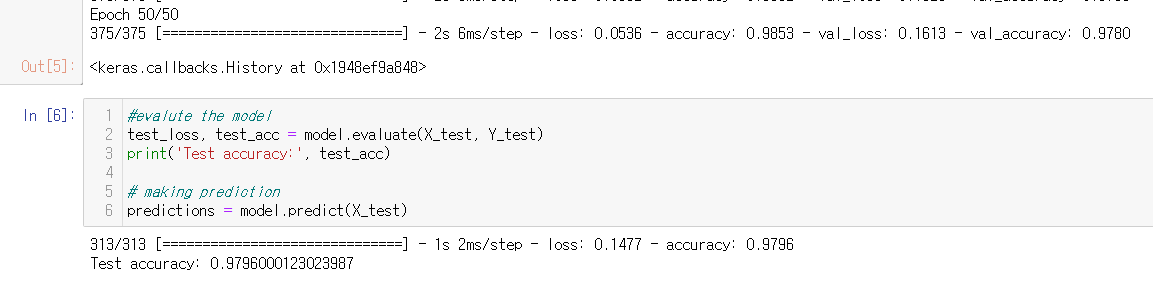
내부 은닉층에서 무작위로 드롭아웃하는 신경망이 테스트 집합에 포함된 낯선 예시를 잘 '잘 일반화'하는 것을 자주 볼 수 있다는 점에 주목하자.
직관적으로 이 현상은 각각의 뉴런이 자기 이웃에 의존할 수 없다는 것을 인식하기 때문에 더 성능이 향상되는 것으로 생각할 수 있다. 또한 중복된 방식으로 정보가 저장되도록 강제하기 때문이다. 테스트하는 동안에는 드롭아웃이 없으므로 이제 고도로 튜닝된 모든 뉴런을 사용하고 있다. 간단히 말해 일반적으로 드롭아웃을 적용할 때 신경망의 성능이 어떻게 되는지 테스트해보는 것이 좋다.
또한 훈련 정확도는 테스트 정확도보다는 높아야 한다. 그렇지 않다면 충분히 오랫동안 훈련을 받지 못한 것일 수 있다.따라서 에폭의 수를 좀 더 늘려야 한다. 그러나 바로 에폭을 늘리기 전에 훈련이 더 빨리 수렴될 수 있도록 몇 가지 다른 개념을 도입할 필요하가 있다. 바로 Optimizer의 살펴본다.
'Deep Learning With Tensorflow > 01.신경망 구현 지식' 카테고리의 다른 글
| 04. 실습: IMDB를 이용한 감정분석과 초매개변수 튜닝과 AutoML, 출력 예측, 역전파에 대한 실용적 개괄에 대해 (0) | 2021.10.30 |
|---|---|
| 03.텐서플로 2.0에서 Accuracy Rate 올릴 수 있는 방법, 정규화와 배치정규화 (0) | 2021.10.29 |
| 01. 퍼셉트론에 대한 이해와 활성화 함수 (0) | 2021.10.18 |


