텐서플로 2.x는 tf.keras와 같은 하이레벨 API를 사용할 것을 권장하지만 내부의 세부 정보를 더 많이 제어해야 하는 경우 텐서플로 1.x의 일반적인 로우레벨 API를 그대로 유지한다. tf.keras와 텐서플로 2.x에는 몇 가지 큰 차이점이 있다.
tf.keras는 순차적 API (Sequential), 함수적 API (Functional), 모델 서브클래싱(Model Subclassing)의 세 가지 프로그래밍 모델과 함께 더 하이레벨 API를 제공한다. 특정 keras.layer를 레고 블록 하나에 비유한다면 학습 모델은 '레고 블록을 쌓는 것'처럼 간단히 생성할 수 있다.
순차적 API
하기에서 보인 Mnis코드를 살펴볼 때 순차적 API를 사용하는 예를 다뤘으므로 다음과 같이 블록을 만들수 있다.
02. 딥러닝의 작동원리필기체 숫자 인식
딥러닝의 작동 원리 층에서 입력 데이터가 처리되는 상세 내용은 일련의 숫자로 이루어진 층의 가중치(weight)에 저장되어 있습니다. 기술적으로 말하면 어떤 층에서 일어나는 변환은 그 층의 가
nicola-ml.tistory.com
아래와 같이 tf.keras.utils.plot_model 함수를 통해 층의 이미지를 그릴 수 있다.
path = 'C:/Users/HANA/PycharmProjects/HANATOUR/AI_Tensorflow/Deep-Learning-with-TensorFlow-2-and-Keras/data_result/'
tf.keras.utils.plot_model(model, to_file= path + '01_mnist_rmsprop_model.png')
함수적 API
함수적 API는 다중 입력, 다중 출력, 비순차 흐름과의 잔존 연결, 공유, 재사용 가능 계층을 포함해 좀 더 복잡한(비선형)위상(topology)으로 모델을 구축하려는 경우에 유용하다. 각 계층은 호출 가능하고(입력은 텐서)각 계층은 텐서를 출력으로 반환한다. 두 개의 개별 입력, 두 개의 개별 로지스틱 회귀를 출력으로, 하나의 공유 모듈을 중간에 갖는 예제를 살펴보자.
현재로서는 계층(즉, 레고 블록)이 내부적으로 수행하는 작업을 이해할 필요가 없고 비선형 네트워크 위상만 관찰하면 된다. 함수가 다른 함수를 호출 할 수 있으므로 모듈은 다른 모듈을 호출할 수 있다는 점도 알아두자.
import tensorflow as tf
def build_model():
# Variable-length sequence of integers
text_input_a = tf.keras.Input(shape=(None,), dtype='int32')
# Variable-length sequence of integers
text_input_b = tf.keras.Input(shape=(None,), dtype='int32')
# Embedding for 1000 unique words mapped to 128-dimensional vectors
shared_embedding = tf.keras.layers.Embedding(1000, 128)
# We reuse the same layer to encode both inputs
encoded_input_a = shared_embedding(text_input_a)
encoded_input_b = shared_embedding(text_input_b)
#two logistic predictions at the end
prediction_a = tf.keras.layers.Dense(1, activation='sigmoid', name='prediction_a')(encoded_input_a)
prediction_b = tf.keras.layers.Dense(1, activation='sigmoid', name='prediction_b')(encoded_input_b)
# this model has 2 inputs, and 2 outputs
# in the middle we have a shared model
model = tf.keras.Model(inputs=[text_input_a, text_input_b],
outputs=[prediction_a, prediction_b])
tf.keras.utils.plot_model(model, to_file="shared_model.png")
build_model()
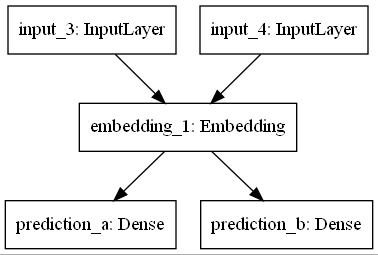
모델 서브클래싱 API (SKIP. UPDATE 중)
모델 서브클래싱은 최고의 유연성을 제공하며 일반적으로 자신의 계층을 정의해야 할 때 사용된다. 비유하자면 표준적고 잘 알려진 레고 블록을 구성하는 대신 자신만의 특수 레고 블록을 만들고자 할 때 유용하다. 복잡도 측면에서는 사실 더 높은 비용이 들기 때문에 서브클래싱은 실제로 필요할 때만 사용해야 한다. 대부분의 경우 순차적 API와 함수적 API가 더 적합하지만 일반적인 파이썬/넘파이 개발자처럼 객체지향적으로 생각하는 것을 선호하는 경우에는 모델 서브클래싱을 사용할 수 있다.
따라서 사용자 정의 계층을 생성하려면 tf.keras.layers.Layer를 서브클래싱 하고 다음 메소드를 구현하면 된다.
- _init_: 선택적으로 이 계층에서 사용할 모든 하위 계층을 정의하는데 사용한다. 모델을 선언할 때의 생성자(constructor)다.
- build: 계층의 가중치를 생성할 때 사용한다. add_weight()로 가중치를 추가할 수 있다.
- Call: 순방향 전달을 정의한다. 계층이 호출되고 함수 형식으로 체인되는 곳이다.
- 선택적으로 get_config()를 사용해 계층을 직렬화(serialize)할 수 있고 from_config()를 사용하면 역직렬화(deserialize)할 수 있다.
콜백
콜백(Callback)은 훈련 중에 동작을 확장하거나 수정하고자 모델로 전달하는 객체다. tf.keras에서 일반적으로 사용되는 몇 가지 유용한 콜백이 있다.
- tf.keras.callbacks.ModelCheckpoint: 이 기능은 정기적으로 모델의 체크포인트를 저장하고 문제가 발생할 때 복구하는 데 사용한다.
- tf.keras.callbacks.LearningRateScheduler: 이 기능은 최적화하는 동안 학습률을 동적으로 변경할 때 사용한다.
- tf.keras.callbacks.EarlyStopping: 이 기능은 검증 성능이 한동안 개선되지 않을 경우 훈련을 중단할 때 사용한다.
- tf.keras.callbacks.TensorBoard: 이 기능은 텐서보드(tensorboard)를 사용해 모델의 행동을 모니터링 할 때 사용한다.
다음과 같이 텐서보드를 사용할 수 있다.
import tensorflow as tf
callbacks = [
#텐서보드 로그를 './logs' 디렉토리에 작성
tf.keras.callbacks.TensorBoard(log_dir='./logs')
]
model.fit(data, labels, batch_size=256, epochs=100, callbacks=callbacks, validation_data=(val_data, val_labels))모델과 가중치 저장
모델을 훈련한 후에는 가중치를 지속적으로 저장해두면 유용할 때가 있다. 다음 코드를 사용하면 가중치 저장을 손쉽게 할 수 있는데, 다음 코드는 텐서플로의 내부 형식으로 저장하고 로드할 수 있다.
model.save_weight('./weight/my_model') #저장
model.load_weight(file_path) #복원
가중치 이외에 모델은 json형식으로 직렬화할 수 있다.
json_string = model.to_json() #저장
model = tf.keras.models.model_from_json(json_string) #복원
모델을 가중치와 최적화 매개변수와 함께 저장하고 싶다면 간단히 다음과 같이하면 된다.
model.save('my_model.h5') #저장
model = tf.keras.models.load_model('my_model.h5') #복원