LightGBM(LGBM) 개요?
Light GBM은 Kaggle 데이터 분석 경진대회에서 우승한 많은 Tree기반 머신러닝 알고리즘에서 XGBoost와 함께 사용되어진것이 알려지며 더욱 유명해지게 되었습니다.
GMB(Gradient Boosting Machine) 이란? 틀린부분에 가중치를 더하면서 진행하는 알고리즘
Gradient Boosting 프레임워크로 Tree기반 학습 알고리즘입니다. 기존의 다른 Tree기반 알고리즘과 다른점은 Tree구조가 수평적으로 확장하는 다른 Tree기반 알고리즘에 비해 수직적으로 확장을 하는것에 있습니다.
즉, Light GBM은 leaf-wise인 반면 다른 알고리즘은 level-wise입니다.

leaf-wise의 장점은 속도가 빠르다는 것이 가장 큰 장점입니다. 데이타의 양이 많아지는 상황에서 빠른 결과를 얻는데 시간이 점점 많이 걸리고 있습니다. Light GBM은 큰 사이즈의 데이타를 다룰 수 있고 실행시킬 때 적은 메모리를 차지합니다.
Light GBM의 단점?
Light GBM은 Leaf-wise growth로 과적합의 우려가 다른 Tree 알고리즘 대비 높은 편입니다. 그러므로 데이터의 양이 적을 경우 Overfitting(과적합)에 취약한 면이 있어 데이타 양이 적을 경우 사용을 자제하는것이 좋습니다.
Light GBM 예시?
400개 트리를 만들어주는 GBM으로 확인을 해보세요.
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from lightgbm import plot_importance
import matplotlib.pyplot as plt
import Common_Module.CMStat as CO
dataset = load_breast_cancer()
ftr = dataset.data
target = dataset.target
X_train, X_test, y_train, y_test = train_test_split(ftr, target, test_size=0.2, random_state=156)
lgbm_wrapper = LGBMClassifier(n_estimators=400)
evals = [(X_test, y_test)]
lgbm_wrapper.fit(X_train, y_train, early_stopping_rounds=100, eval_metric='logloss', eval_set=evals, verbose=True)
pred = lgbm_wrapper.predict(X_test)
pred_proba = lgbm_wrapper.predict_proba(X_test)[:1]
CO.get_clf_eval(y_test, pred)
fig, ax = plt.subplots(figsize=(10,12))
plot_importance(lgbm_wrapper, ax=ax)
plt.show()get_clf_eval함수는 하기와 같습니다.
# 평가지표 출력하는 함수 설정
def get_clf_eval(y_test, y_pred=None, pred_proba=None):
confusion = confusion_matrix(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
F1 = f1_score(y_test, y_pred)
AUC = roc_auc_score(y_test, y_pred, pred_proba)
print('오차행렬:\n', confusion)
print('\n정확도: {:.4f}'.format(accuracy))
print('정밀도: {:.4f}'.format(precision))
print('재현율: {:.4f}'.format(recall))
print('F1: {:.4f}'.format(F1))
print('AUC: {:.4f}'.format(AUC))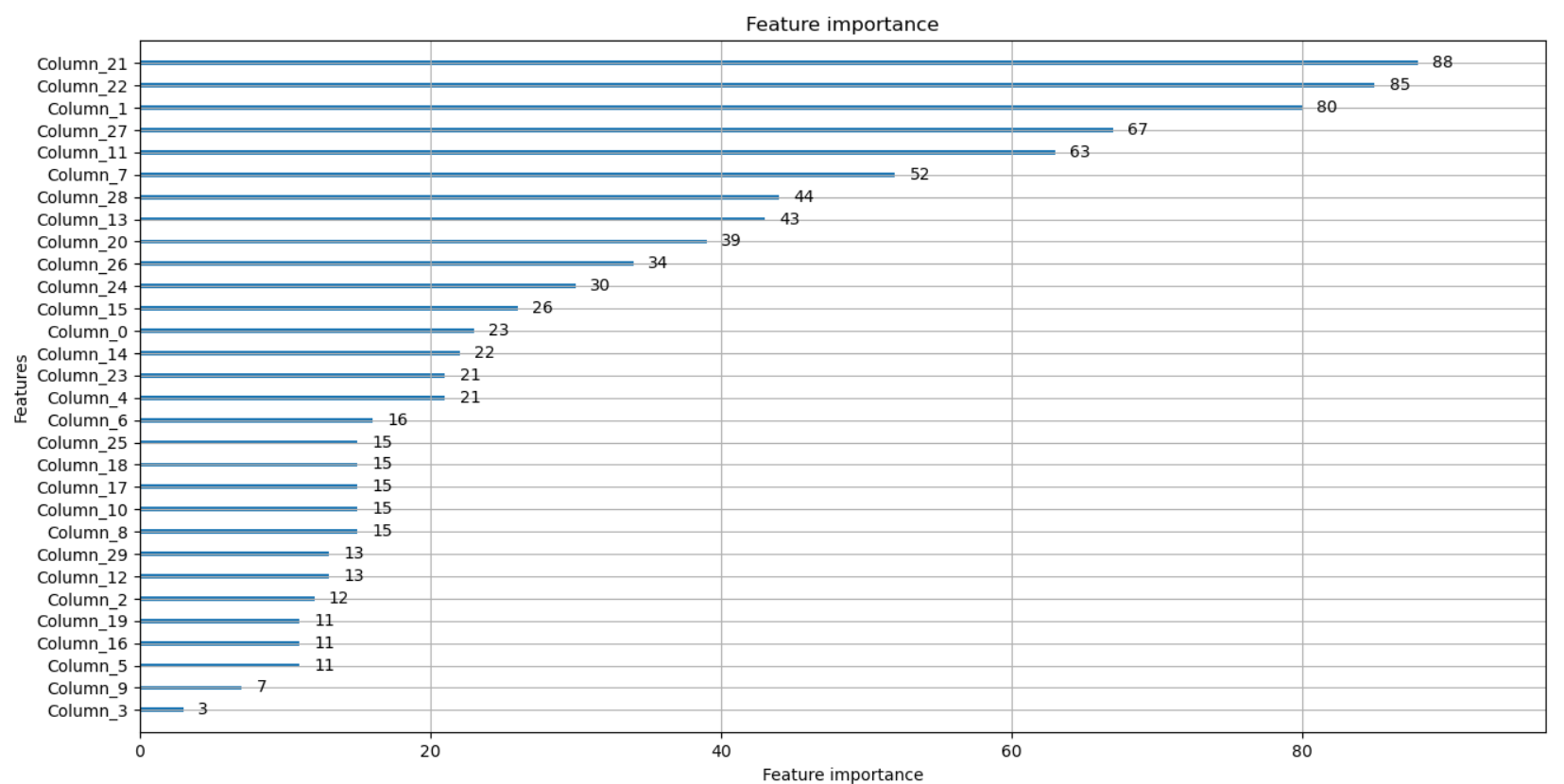
Light GBM의 파라미터에 대해?
LGBM의 경우 복잡한 것은 파라미터 튜닝입니다. Light GBM은 100개 이상의 파라미터를 커버하고 있기 때문입니다.
Light GBM의 가장 베이직한 파라미터를 아는 것이 구현 시 매우 중요합니다.
max_depth : Tree의 최대 깊이를 말합니다. 이 파라미터는 모델 과적합을 다룰 때 사용됩니다. 만약 여러분의 모델이 과적합된 것 같다고 느끼신다면 제 조언은 max_depth 값을 줄이라는 것입니다.
min_data_in_leaf : Leaf가 가지고 있는 최소한의 레코드 수입니다. 디폴트값은 20으로 최적 값입니다. 과적합을 해결할 때 사용되는 파라미터입니다.
feature_fraction : Boosting (나중에 다뤄질 것입니다) 이 랜덤 포레스트일 경우 사용합니다. 0.8 feature_fraction의 의미는 Light GBM이 Tree를 만들 때 매번 각각의 iteration 반복에서 파라미터 중에서 80%를 랜덤하게 선택하는 것을 의미합니다.
bagging_fraction : 매번 iteration을 돌 때 사용되는 데이터의 일부를 선택하는데 트레이닝 속도를 높이고 과적합을 방지할 때 주로 사용됩니다.
early_stopping_round : 이 파라미터는 분석 속도를 높이는데 도움이 됩니다. 모델은 만약 어떤 validation 데이터 중 하나의 지표가 지난 early_stopping_round 라운드에서 향상되지 않았다면 학습을 중단합니다. 이는 지나친 iteration을 줄이는데 도움이 됩니다.
lambda : lambda 값은 regularization 정규화를 합니다. 일반적인 값의 범위는 0 에서 1 사이입니다.
min_gain_to_split : 이 파라미터는 분기하기 위해 필요한 최소한의 gain을 의미합니다. Tree에서 유용한 분기의 수를 컨트롤하는데 사용됩니다.
max_cat_group : 카테고리 수가 클 때, 과적합을 방지하는 분기 포인트를 찾습니다. 그래서 Light GBM 알고리즘이 카테고리 그룹을 max_cat_group 그룹으로 합치고 그룹 경계선에서 분기 포인트를 찾습니다. 디폴트 값은 64 입니다.
Task : 데이터에 대해서 수행하고자 하는 임무를 구체화합니다. train 트레이닝일 수도 있고 predict 예측일 수도 있습니다.
application : 가장 중요한 파라미터로, 모델의 어플리케이션을 정하는데 이것이 regression 회귀분석 문제인지 또는
classification 분류 문제인지를 정합니다. Light GBM에서 디폴트는 regression 회귀분석 모델입니다.
- regression: 회귀분석
- binary: 이진 분류
- multiclass: 다중 분류
boosting : 실행하고자 하는 알고리즘 타입을 정의합니다. 디폴트값은 gdbt 입니다.
- gdbt : Traditional Gradient Boosting Decision Tree
- rf : Random Forest
- dart : Dropouts meet Multiple Additive Regression Trees
- goss : Gradient-based One-Side Sampling
num_boost_round : boosting iteration 수로 일반적으로 100 이상입니다.
learning_rate : 최종 결과에 대한 각각의 Tree에 영향을 미치는 변수입니다. GBM은 초기의 추정값에서 시작하여 각각의Tree 결과를 사용하여 추정값을 업데이트 합니다. 학습 파라미터는 이러한 추정에서 발생하는 변화의 크기를 컨트롤합니다. 일반적인 값은 0.1, 0.001, 0.003 등등이 있습니다.
num_leaves : 전체 Tree의 leave 수 이고, 디폴트값은 31입니다.
device : 디폴트 값은 cpu 인데 gpu로 변경할 수도 있습니다.
metric : 모델을 구현할 때 손실을 정하기 때문에 중요한 변수 중에 하나입니다. regression과 classification 을 위한 일반적인 손실 값이 아래에 나와있습니다.
- mae : mean absolute error
- mse : mean squared error
- binary_logloss : loss for binary classification
- multi_logloss : loss for multi classification
하이퍼 파라미터 튜닝 방안
num_levels의 개수를 중심으로 min_child_samples(min_data_in_leaf), max_depth를 함께 조정하면서 모델의 복잡도를 줄이는 것이 기본 튜닝 방안입니다.
- num_levels는 개별 트리가 가질 수 있는 최대 리프의 개수이고 LightGBM 모델의 복잡도를 제어하는 주요 파라미터입니다. 일반적으로 num_leaves의 개수를 높이면 정확도가 높아지지만, 반대로 트리의 깊이가 깊어지고 모델이 복잡도가 커져 과적합 영향도가 커집니다.
- min_data_in_leaf는 사이킷런 래퍼 클래스에서는 min_child_samples로 이름이 바뀝니다. 과적합을 개선하기 위한 중요한 파라미터입니다. num_leaves와 학습 데이터의 크기에 따라 달라지지만, 보통 큰 값으로 설정하면 트리가 깊어지는 것을 방지합니다.
- max_depth는 명시적으로 깊이의 크기를 제한합니다. num_leaves, min_data_in_leaf와 결합해 과적합을 개선하는 데 사용합니다.
learning_rate를 작게 하면서 n_estimators를 크게 하는 것은 부스팅 계열 튜닝에서 가장 기본적인 튜닝 방안이므로 이를 적용하는 것도 좋습니다. 물론 n_estimators를 너무 크게 하는 것은 과적합으로 오히려 성능이 저하될 수 있습니다.
이밖에 과적합을 제어하기 위해서 reg_lambda, reg_alpha와 같은 regularization을 적용하거나 학습 데이터에 사용할 피처의 개수나 데이터 샘플링 레코드 개수를 줄이기 위해 colsample_bytree, subsample파라미터를 적용할 수 있습니다.
'ML with SckitLearn' 카테고리의 다른 글
| Kmeans의 K값을 정하는 기준 : Elbow Method, Silhouette Score(실루엣 스코어) (0) | 2020.12.15 |
|---|---|
| 데이터 전처리하기 : 레이블 인코딩 (Label Encoding), 원-핫 인코딩(One-Hot Encoding), get_dummies()를 Pandas에서 사용하기 (0) | 2020.12.09 |
| K-Means 알고리즘의 원리와 이해 한판에 배워보기 (0) | 2020.12.05 |
| 머신러닝, 클러스터 가우시안 가상데이터 생성하는 make_blobs를 이용한 K-means 실습 (Elbow Method 사용) (0) | 2020.12.03 |
| Faiss를 이용한 K-means구현 [사이킷런에 비해 8X 빠르고, 27X 적은 에러 구현] (0) | 2020.11.14 |
| 로지스틱 회귀 : Logistic Regression, 시그모이드(sigmoid)를 이용한 분류 회귀 (0) | 2020.10.25 |
| 라쏘 / 엘라스틱넷 회귀 : Lasso / ElasticNet Model 이란? Scikit Learn에서의 실습 (0) | 2020.10.24 |
| 릿지 회귀 : Ridge Model 이란? Scikit Learn에서의 실습 (0) | 2020.10.24 |



