반응형
make_blobs 함수는 가우시안 정규분포를 이용해 가상 데이터를 생성합니다. make_blobs는 일반적으로 클러스링 가상데이터를 생성하는데 사용합니다. 클러스터 알고리즘인 K-Means의 실습을 편하게 하기 위해 사용하면 도움이 됩니다.
make_blobs 함수의 인수와 반환값은 다음과 같다.
- Input Parameter
- n_samples : 표본 데이터의 수, 디폴트 100
- n_features : 독립 변수의 수, 디폴트 20
- centers : 생성할 클러스터의 수 혹은 중심, [n_centers, n_features] 크기의 배열. 디폴트 3
- cluster_std: 클러스터의 표준 편차, 디폴트 1.0
- center_box: 생성할 클러스터의 바운딩 박스(bounding box), 디폴트 (-10.0, 10.0))
- shuffle: TRUE하면 숫자를 랜덤으로 섞어주는 역할을 한다.
- Return Parameter:
- X : [n_samples, n_features] 크기의 배열: 독립 변수
- y : [n_samples] 크기의 배열: 종속 변수
make_blobs를 이용한 K-Means 실습
샘플데이터를 만들기 위해 make_blobs를 사용한 후 그에 따른 그래프를 그려봅니다.
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(
n_samples=150,
n_features=2,
centers=3,
cluster_std=0.5,
shuffle=True,
random_state=0
)
plt.scatter(
X[:, 0],
X[:, 1],
c='white',
marker='o',
edgecolors='black',
s=50
)
plt.show()
K-means를 이용하여 상기 Random Data를 적용하고 분포를 이미지로 그려봅니다.
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, init='random', n_init=10, max_iter=300, tol=1e-04, random_state=0)
y_km = km.fit_predict(X)
plt.scatter(X[y_km==0,0], X[y_km==0, 1], s=50, c='lightgreen', marker='s', edgecolors='black', label='cluster 1')
plt.scatter(X[y_km==1,0], X[y_km==1, 1], s=50, c='orange', marker='o', edgecolors='black', label='cluster 2')
plt.scatter(X[y_km==2,0], X[y_km==2, 1], s=50, c='lightblue', marker='v', edgecolors='black', label='cluster 3')
plt.scatter(km.cluster_centers_[:,0], km.cluster_centers_[:,1], s=250, marker='*', c='red', edgecolors='black', label='centroid')
plt.legend(scatterpoints=1)
plt.grid()
plt.show()K-Means의 단점은 최적의 Cluster 수인 K가 몇개의 클러스터가 최적인지 알 수 없고 직접 지정을 해야 한다는 것입니다. 만약 잘못된 Cluster를 정하면 데이타 왜곡이 발생할 수 있습니다.

이를 보완하기 위해 Elbow Method는 매우 좋은 방법이 될 수 있습니다. 주어진 모델에 대한 최적 군집 수 K를 추정하는 데 유용한 그래픽 도구입니다. Elbow Method의 개념은 왜곡이 가장 빠르게 감소하기 시작하는 K값을 식별하는 하는 것입니다.
여기서는 Elbow의 기울기가 급격하게 줄어드는 3을 Cluster 갯수로 지정하면 됩니다.
distortions = []
for i in range(1,11):
km = KMeans(
n_clusters=i,
init='random',
n_init=10,
max_iter=300,
tol=1e-04,
random_state=0
)
km.fit(X)
distortions.append(km.inertia_)
plt.plot(range(1,11), distortions, marker='o')
plt.xlabel('Number of Cluster')
plt.ylabel('Distortion')
plt.show()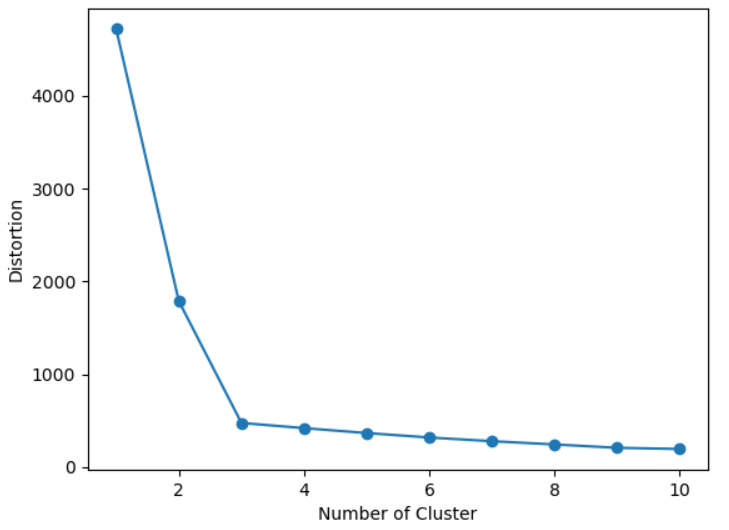
반응형
'ML with SckitLearn' 카테고리의 다른 글
| 심장질환 발병 예측하기 - SVM, K Nearset Neighbour, ANN Multilayer Perceptron (0) | 2021.03.27 |
|---|---|
| Kmeans의 K값을 정하는 기준 : Elbow Method, Silhouette Score(실루엣 스코어) (0) | 2020.12.15 |
| 데이터 전처리하기 : 레이블 인코딩 (Label Encoding), 원-핫 인코딩(One-Hot Encoding), get_dummies()를 Pandas에서 사용하기 (0) | 2020.12.09 |
| K-Means 알고리즘의 원리와 이해 한판에 배워보기 (0) | 2020.12.05 |
| Light GBM(LGBM)의 개요와 파라미터 정의에 대해 (0) | 2020.11.19 |
| Faiss를 이용한 K-means구현 [사이킷런에 비해 8X 빠르고, 27X 적은 에러 구현] (0) | 2020.11.14 |
| 로지스틱 회귀 : Logistic Regression, 시그모이드(sigmoid)를 이용한 분류 회귀 (0) | 2020.10.25 |
| 라쏘 / 엘라스틱넷 회귀 : Lasso / ElasticNet Model 이란? Scikit Learn에서의 실습 (0) | 2020.10.24 |



